My 17-days old Seagate Barracuda 7200.9 300GB disk was giving a lot of error two days ago. There were a bunch of errors in my syslog:
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
sd 2:0:0:0: SCSI error: return code = 0x8000002
sda: Current: sense key: Medium Error
Additional sense: Unrecovered read error - auto reallocate failed
end_request: I/O error, dev sda, sector 212833665
Buffer I/O error on device sda1, logical block 106416801
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04 |
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
sd 2:0:0:0: SCSI error: return code = 0x8000002
sda: Current: sense key: Medium Error
Additional sense: Unrecovered read error - auto reallocate failed
end_request: I/O error, dev sda, sector 212833665
Buffer I/O error on device sda1, logical block 106416801
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
ata1: status=0x51 { DriveReady SeekComplete Error }
ata1: error=0x40 { UncorrectableError }
ata1: translated ATA stat/err 0x51/40 to SCSI SK/ASC/ASCQ 0x3/11/04
Yes, that’s right. After 17 days so I can’t get a one-to-one replacement from the shop.
SMARTD Logs:
Error 6892 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT
Error 6891 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT
Error 6890 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT |
Error 6892 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT
Error 6891 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT
Error 6890 occurred at disk power-on lifetime: 427 hours (17 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 b4 95 af e0 Error: UNC at LBA = 0x00af95b4 = 11507124
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
25 00 d0 b0 95 af e0 00 01:47:04.861 READ DMA EXT
25 00 d0 b0 95 af e0 00 01:47:03.048 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:47:01.243 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:59.447 READ DMA EXT
25 00 d8 a8 95 af e0 00 01:46:57.650 READ DMA EXT
Here’s the disk label:

I blamed the disk. My friend Azidin had a different idea. He said that it might be the SATA controller card that I installed on my computer that’s causing the errors. I didn’t believe him.
That night I tested the disk with Azidin. There were a lot of bad sectors!!!!! But still, I refused to blame the SATA controller card.
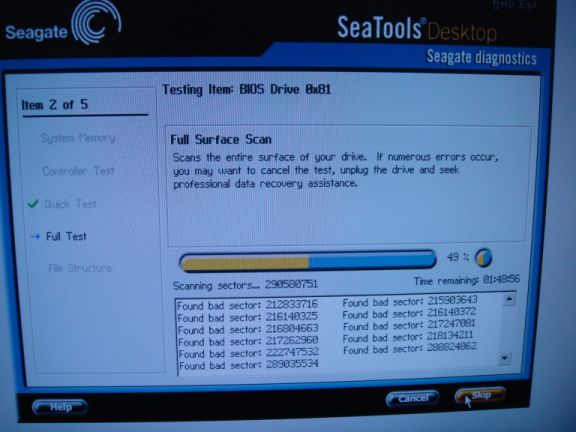
After work on 23 June, I immediately rushed to the shop, hoping that they would give me some help, or keep my disk for checking during the weekend but they (C-Zone) rejected me saying that their service center is closed and asked me to come the next day. I was disappointed. But I didn’t leave Low Yat plaza before buying a 200GB Maxtor disk from Startec, just in case if it’ll take months to get my disk repaired.

Back home, I installed the disk onto the same SATA controller card. The next day, I received these from my syslog:
end_request: I/O error, dev sda, sector 132826840
Buffer I/O error on device sda2, logical block 8210
lost page write due to I/O error on sda2
ATA: abnormal status 0xD0 on port 0x9807
ATA: abnormal status 0xD0 on port 0x9807
ATA: abnormal status 0xD0 on port 0x9807
ReiserFS: sda2: warning: journal-837: IO error during journal replay
REISERFS: abort (device sda2): Write error while updating journal header in flush_journal_list
REISERFS: Aborting journal for filesystem on sda2
ata1: command 0x25 timeout, stat 0xd0 host_stat 0x1
ata1: translated ATA stat/err 0xd0/00 to SCSI SK/ASC/ASCQ 0xb/47/00
ata1: status=0xd0 { Busy }
sd 0:0:0:0: SCSI error: return code = 0x8000002
sda: Current: sense key: Aborted Command
Additional sense: Scsi parity error
end_request: I/O error, dev sda, sector 133810704 |
end_request: I/O error, dev sda, sector 132826840
Buffer I/O error on device sda2, logical block 8210
lost page write due to I/O error on sda2
ATA: abnormal status 0xD0 on port 0x9807
ATA: abnormal status 0xD0 on port 0x9807
ATA: abnormal status 0xD0 on port 0x9807
ReiserFS: sda2: warning: journal-837: IO error during journal replay
REISERFS: abort (device sda2): Write error while updating journal header in flush_journal_list
REISERFS: Aborting journal for filesystem on sda2
ata1: command 0x25 timeout, stat 0xd0 host_stat 0x1
ata1: translated ATA stat/err 0xd0/00 to SCSI SK/ASC/ASCQ 0xb/47/00
ata1: status=0xd0 { Busy }
sd 0:0:0:0: SCSI error: return code = 0x8000002
sda: Current: sense key: Aborted Command
Additional sense: Scsi parity error
end_request: I/O error, dev sda, sector 133810704
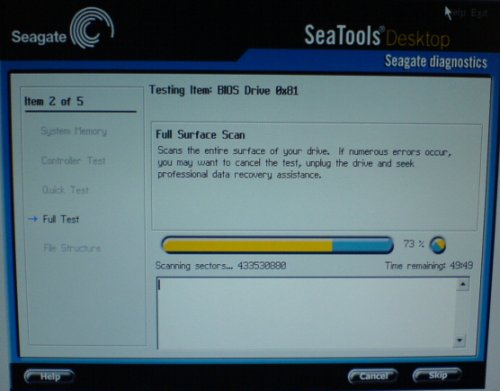
I started to believe that the controller card might be causing the problems. What are the odds that all my disks end up producing errors like these? I decided to buy a new motherboard with a built-in SATA controller, without spending too much. Also, I have an unused socket 478 Celeron, so after some research, I decided to get an ASUS P4P800-MX that’s still available in Cycom. The very same night, I ran Seagate Desktop on my older disk – low-level format (zero fill). It took hours but totally worth it. This morning when the process finished I ran another surface scan of the 300GB disk and all bad sectors are gone. Pheww! I decided not to send it to the shop, but continue using it with caution. It carries a 5-year warranty anyway.
So today I went and bought a P4P800-MX from Cycom, with two sticks of 512MB DDR (to utilize dual-channel memory bus). I have just finished installing the 300GB Seagate disk plus the 200GB Maxtor disk on the new motherboard. Everything looks good.
The cuplrit? Here it is:

I don’t think it’s the chip. Maybe the card is defective. I bought it at Sri, in a plastic package (they hang such packages on a wall like in a supermarket). I thought of returning it, but I’m too tired to argue with the shop.
Oh well. I am all happy now. Thanks to Azidin for his help, and of course to my dear wife for her understanding of this matter.
